Nicolas Ferré
Data Scientist Expert
Take control of your data with Generative AI

In recent years, generative AI has created a revolution in the industry by enabling a new range of use cases that were very difficult to automate in the past. One common use case where generative AI shines is to communicate in a natural and efficient way with a vast database.
In this blogpost, we will show how to take advantage of generate AI in a case where your website allows users to search documents in a large database. Even if a search bar is available to find relevant documents by keyword, a more user-friendly experience would be to propose an assistant with which users can interact in natural language to find relevant information or obtain direct answers in a more efficient way.
To demonstrate this use case, ARHS Spikeseed has developed an assistant able to answer several type of questions related to data contained in a database. This article explains in detail the capabilities of this assistant and how it was built.
Context
The assistant is able to answer questions related to European public procurement notices. These notices describe purchases made by public authorities, including works, goods, or services from various suppliers, and can be consulted on the TED website.
A notice is available in several formats (XML, PDF, HTML, …) and contains structured information on a specific contract. Here is an example of notice found on the TED website:

The notice contains various information, such as a title, descriptions, budgetary values, etc. In the “Summary” section, we find structured metadata associated to the notice:

For demonstrating purposes of our assistant, we will consider one million notices. For each notice, we retrieve an important part of the metadata, as well as the short description.
The assistant in action
Now that we have seen what data the assistant can access, let’s see it in action.
The assistant is able to extract information and answer questions about a given notice. For example, the notice 226749-2021 talks about an online event. The assistant can be used to quickly obtain the key points of this event:
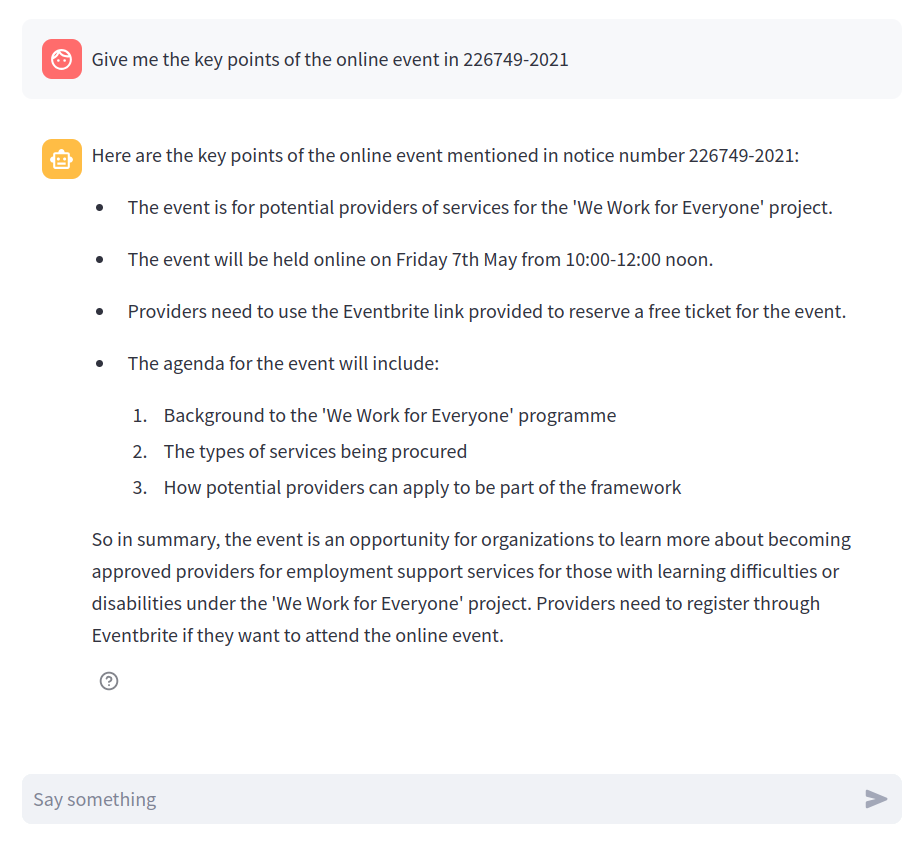
However, we usually don’t know in advance in which notice the information can be found. Hopefully, the assistant can also answer questions that are not related to a specific notice. We can go back to the previous example and replace the notice identifier by the exact name of the event, and we see that the assistant is still able to give a correct answer:
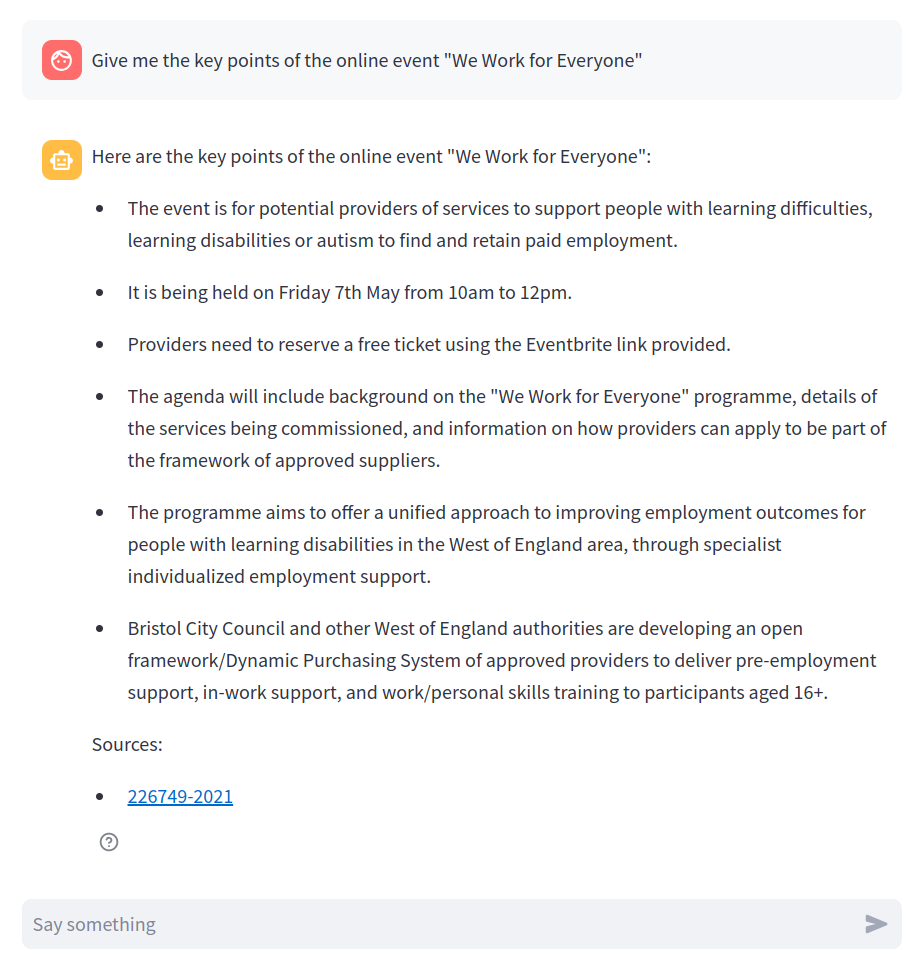
Note that the assistant also lists the relevant notices that were used to generate the answer, so that the user can verify it if necessary.
In addition to questions related to notice text content, it is also possible to ask questions related to metadata of the notices. For example, we can obtain specific metadata of a given notice:
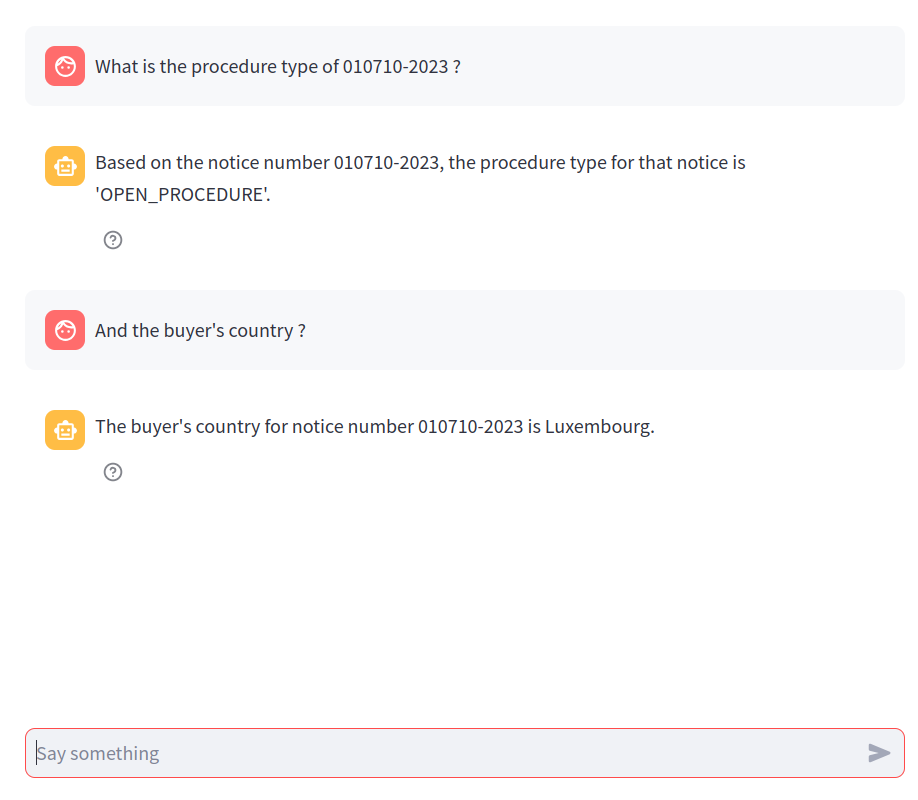
Note here that the assistant is able to answer questions based on previous messages in the discussion, so that it is more natural and convenient for the users.
We can also go further and ask more complex questions, like counting or listing notices matching specific criteria, or ask questions indirectly related to notices:
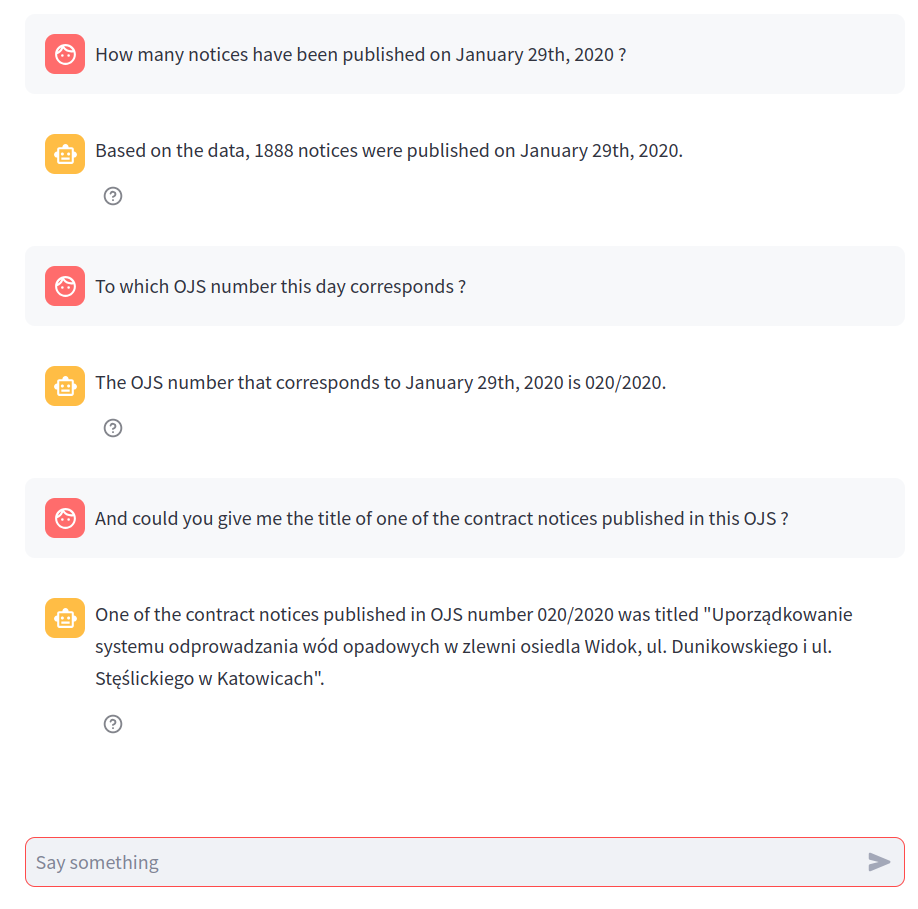
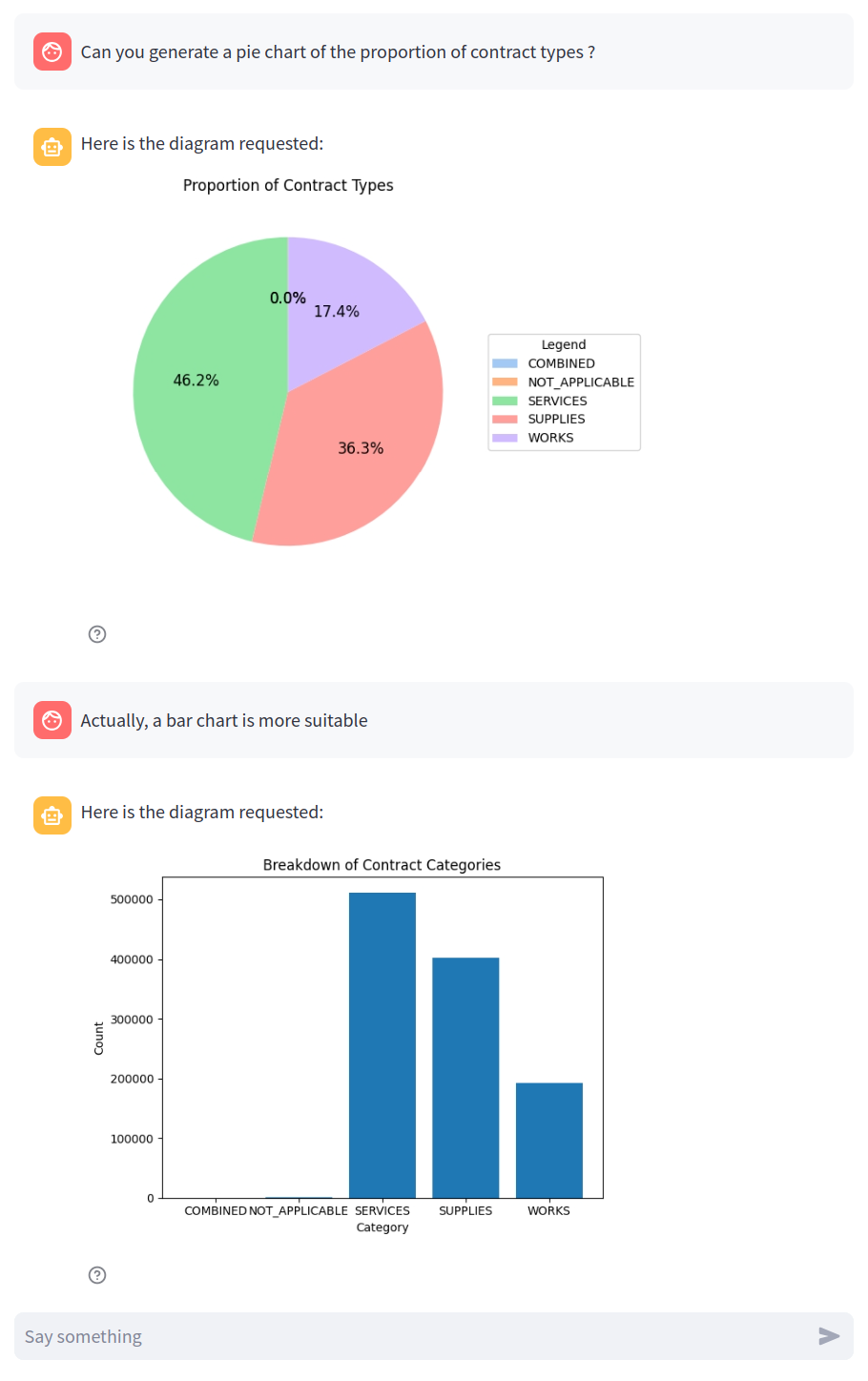
Generative AI enables many other features to be integrated. For instance, we can allow users to generate diagrams to facilitate visualization of the database. Here is an example with the visualization of the notice contract types, a supported metadata:
Behind the scene
Now that we have seen the capabilities of the assistant, let’s discover how it works under the hood.
Architecture
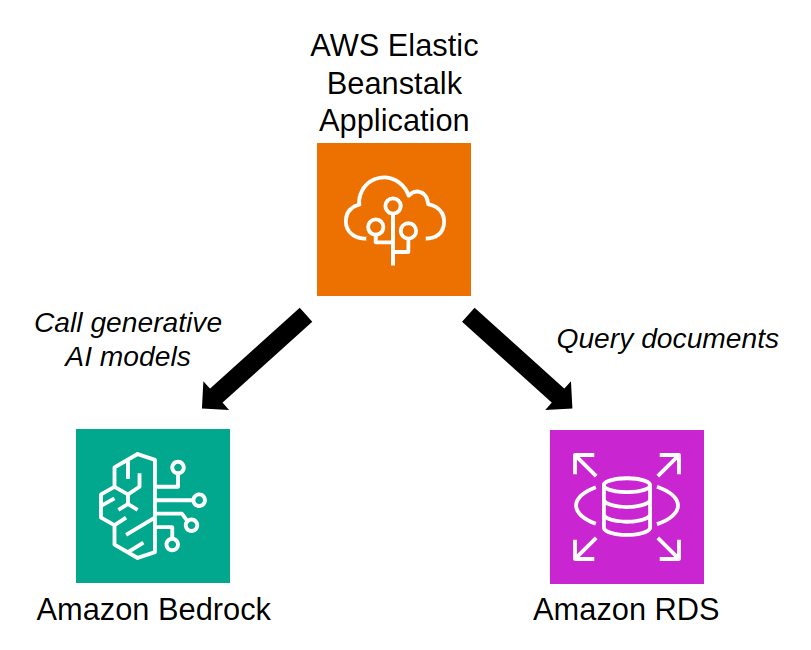
The assistant is an application written in Python and deployed on AWS:
- The application has been deployed using AWS Elastic Beanstalk, a fully managed service used to simplify deployment of applications in the cloud.
- The notices are stored in a PostgreSQL database hosted using Amazon RDS.
- The core part of the application rely on generative AI to generate answers of user’s questions in natural language. We have used a text generation model called Claude, available directly in Amazon Bedrock though an API. Bedrock is a fully managed service that enables access to generative AI models like Large Language Models (models able to perform general purpose text understanding and generation). It has a pay-as-you-go model, which means it is not needed to run a costly infrastructure paid per hour to host these models, but simply pay per request sent to Bedrock.
The following diagram shows how these AWS services interact with the application:
Assistant logic
Several techniques have been put in place to handle the following kinds of questions supported by the assistant:
- Questions related to specific notice content,
- Questions related to any notice content,
- Questions related to notice metadata.
1. Questions related to specific notice content
The following diagram gives a high level overview of how this type of question is handled by the assistant:
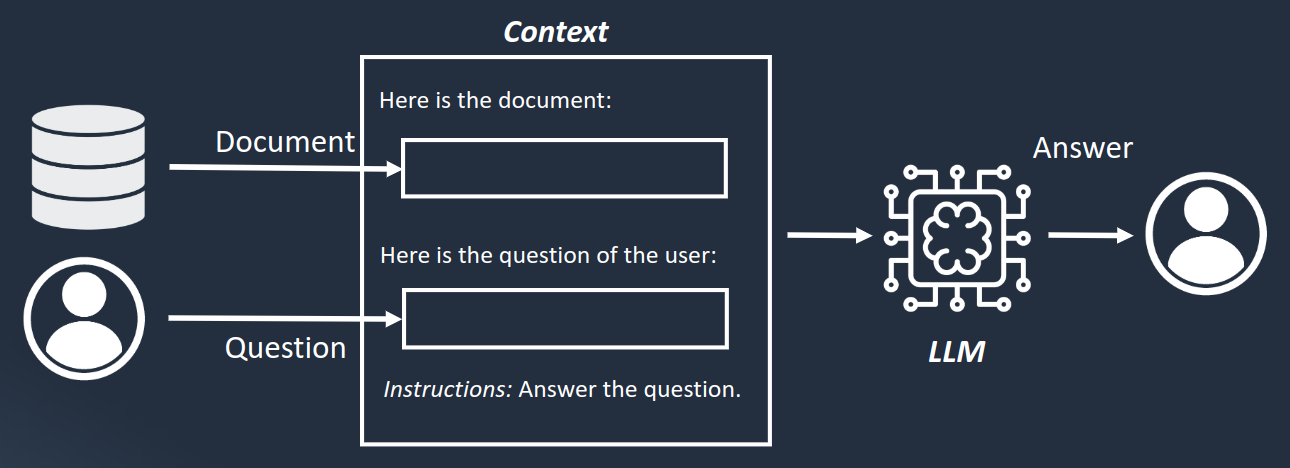
When the user sends a question to the assistant, it internally extracts the notice identifier, retrieves the notice content from the database and uses the obtained information to construct a context for the LLM. The goal of a context is to provide relevant data to the LLM to perform the text generation and avoid providing a general answer not related to the document specified. With a context containing enough information, the LLM is able to generate a natural answer to the user.
Note that LLM context has a limited size that depends on the used LLM. In case the notice content is too large, it is possible to summarize it before injecting the content into the final context:
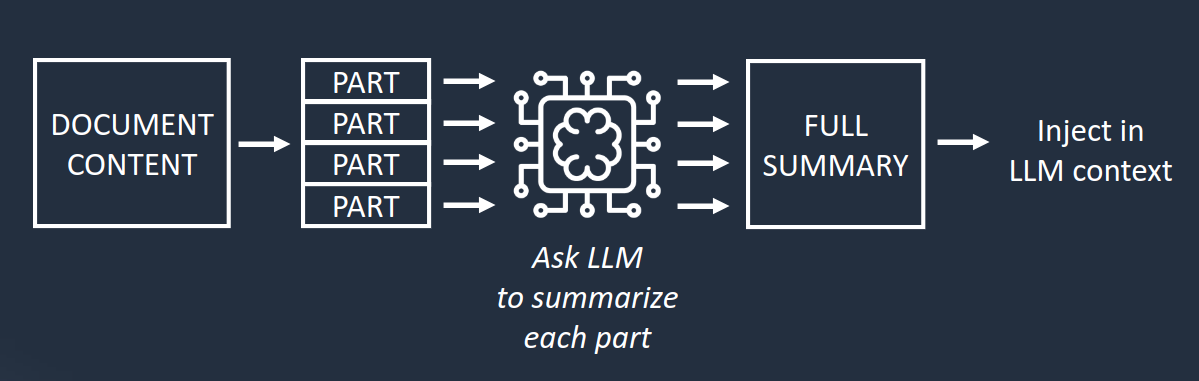
The notice content is split in smaller parts, sent independently to the LLM to be summarized, and all obtained summaries are merged to obtain the full summary of the notice.
2. Questions related to any notice content
In case the question is not related to a particular notice, it is needed to filter the notice parts present in the database to only keep the most relevant, before injecting them in the context to generate an answer. To perform this, a widely used technique is the Retrieval-Augmented Generation:
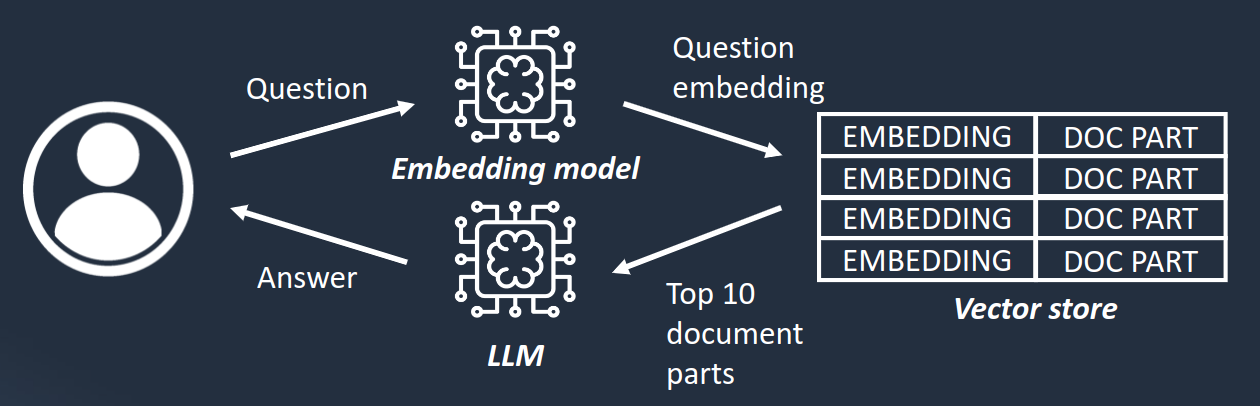
The technique relies on embedding vectors, which is a numerical vector that represents the meaning of a text. If two vectors are close, it means the two texts most probably talk about the same subjects. These vectors are generated using a dedicated machine learning model, and in the context of our assistant, the model Titan Text Embeddings provided by Amazon Bedrock has been used.
All the notices known by the assistant are stored in a vector store, a database that contains notice contents associated with their embedding vector. For this demonstration, we use PostgreSQL with the pgvector extension, but many other vector stores are available. The choice of the vector store depends on your use case and your existing infrastructure. When the user sends a question to the assistant, the embedding of the question is internally created and compared to all the embeddings inside the vector store. This way, we can obtain the notices closest to the question in terms of meaning. These top notices can then be injected in the LLM context with the user’s question so that the LLM can generate an answer.
3. Questions related to notice metadata
Metadata cannot be handled by the Retrieval-Augmented Generation technique as this technique is working on text contents. To support questions related to metadata, an alternative solution can be used, based on database queries:
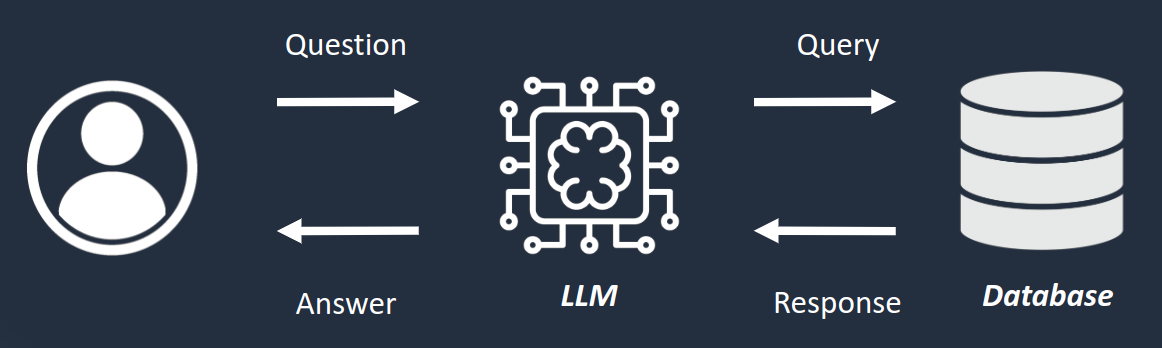
The question of the user and the database schema is internally passed to the LLM to generate a database query. As a PostgreSQL database is used, the LLM generates an SQL query necessary to retrieve relevant information. This query is then run to retrieve data that are injected in the LLM context to create the final answer.
Because of how this technique works, any question that can be expressed as a SQL query should be supported by the assistant.
Conclusion
This article has presented an overview of the capabilities of generative AI with a concrete use case, where this technology can facilitate access to information for end users. We have also seen the different techniques that can be used to put in place such a solution.
It is also important to note that although the case presented focuses on a question-answer assistant, generative AI can in fact be used on a wider range of use cases. Any type of functionality based on text understanding or text generation can be implemented using the techniques presented in this article, including automatic text extraction from documents, search enhancement, data validation, …