Léo Alonzo
Data Scientist Junior
Enhance your information retrieval strategy with RAG and advanced query techniques

Over the past few years, Retrieval-Augmented Generation (RAG) has emerged as a powerful solution for improving how users interact with large data sets. Instead of relying on basic keyword searches, RAG leverages retrieval and generation techniques to deliver more intuitive and precise responses.
In this post, we focus on the specific aspect of information retrieval. By using advanced techniques such as HyDE or query rewriting, we’ll demonstrate how these methods can enhance the way users find relevant information, making the process more precise.
Context
To test the advanced techniques, we use data from the EU Office Publications, specifically the EU Law in Force dataset. This dataset contains European law documents in PDF or XHTML format. For the RAG system, we split the data into chunks of 500 tokens each and store them in an Elasticsearch vector store.
We use Claude-3-haiku via AWS Bedrock to test the application. Below is the implementation of the API integration for Claude-3-haiku.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import boto3
import json
client = boto3.client(service_name="bedrock-runtime")
def generate_answer(prompt, prompt_system="", model = "anthropic.claude-3-haiku-20240307-v1:0", temperature=0.1):
body = {
"prompt": f"\n\nSystem: {prompt_system}\n\nHuman: {prompt}\n\nAssistant:",
"max_tokens_to_sample": 1024,
"temperature": temperature,
}
response = client.invoke_model(
modelId=model,
contentType="application/json",
accept="application/json",
body=json.dumps(body)
)
response_body = json.loads(response['body'].read())
return response_body
Advanced RAG techniques
We explore advanced methods to enhance traditional RAG. In classic RAG, embeddings are used to find and rank relevant document chunks by comparing the query’s embedding with the embeddings of the stored chunks.
Query rewriting
Query Rewriting is not just about improving immediate query results; it’s a foundational method for many advanced RAG techniques. By refining or expanding a user’s original question, it enables the system to retrieve more precise and relevant documents. For example, a query like “data privacy law” might be rewritten as “What are the key regulations on data privacy in the EU in 2023?”. This rewording adds clarity and specificity, allowing the system to capture a broader and more accurate range of results.
Rewriting queries also serves as the groundwork for more advanced techniques like RAG Fusion, where multiple variations of the query are processed to increase coverage and precision.
Re-ranking
Re-ranking is not a search method in itself, but rather a technique for improving the quality of results by combining outputs from multiple retrieval methods. After the initial retrieval phase, where different search strategies (like dense retrieval or keyword-based search) produce a set of documents, re-ranking reorganizes these results based on relevance.
This process can involve techniques like semantic similarity scoring or contextual relevance to fine-tune the ranking. By applying re-ranking, we ensure that the most accurate and contextually appropriate documents rise to the top, providing users with better-quality responses.
Now that we’ve covered query rewriting and re-ranking, it’s important to note that these two concepts are not standalone techniques. Instead, they serve as foundational steps that are applied within more advanced methods. In the following sections, we explore how HyDE and RAG Fusion utilize both query rewriting and re-ranking to improve information retrieval and enhance the quality of generated results.
Hypothetical Documents Embedding (HyDE)
HyDE (Hypothetical Document Embeddings) enhances retrieval in RAG systems by generating plausible hypothetical documents that simulate potential answers to user queries. This helps mitigate the gap between user queries (which are typically short and structured as questions or keywords) and document chunks (which are longer, often full paragraphs).
The following image illustrates the gap, but it’s important to note that, in reality, embedding vectors operate in hundreds or even thousands of dimensions, while the image is a simplified 2D representation for clarity. HyDE helps reduce the gap between the two set, leading to more accurate semantic search results:
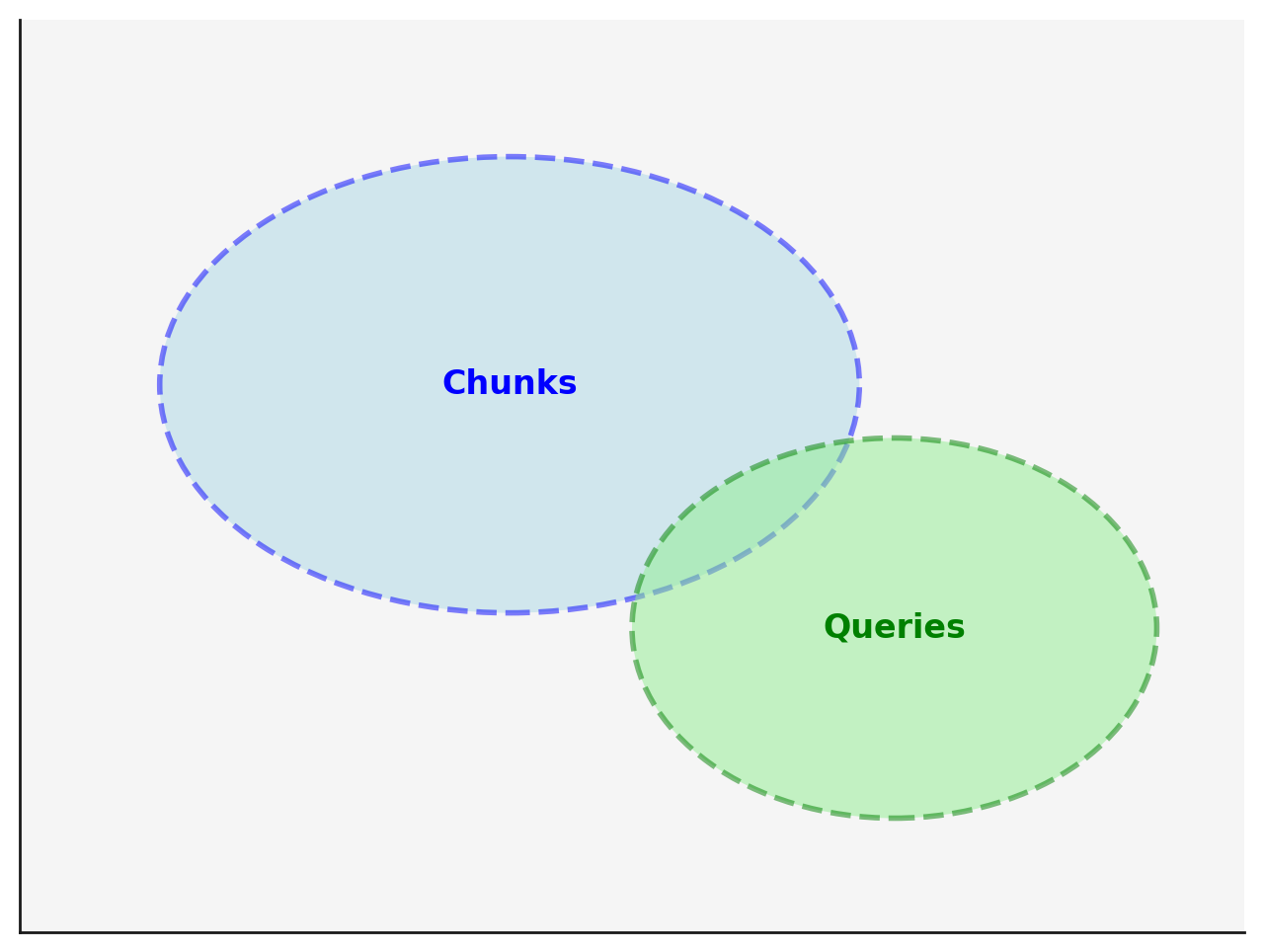
In addition to aligning formats, the hypothetical documents created by HyDE are plausible responses, meaning they closely resemble real answers the system might retrieve. This additional factor makes the comparison between query and chunk embeddings even more accurate.
Implementing this technique is straightforward. First, we define the prompt to generate hypothetical documents:
1
2
3
4
5
6
7
prompt_system_with_question = f"""Please write a passage to answer the question
Try to include as many key details as possible. The question are asked to EU law in force.
question : {prompt}"""
list_hyde = [prompt]
Next, we can generate multiple hypothetical documents to improve the embeddings. This process can be parallelized to speed it up:
1
2
3
4
5
6
7
8
9
10
11
import concurrent
def generate_single_answer(_):
chunks = generate_answer(prompt_system_with_question, prompt_system="", temperature=0.8)
answer = ''.join(chunks)
return answer
with concurrent.futures.ThreadPoolExecutor(max_workers=k) as executor:
futures = [executor.submit(generate_single_answer, _) for _ in range(k)]
for future in concurrent.futures.as_completed(futures):
list_hyde.append(future.result())
Now, we have two ways to use these hypothetical documents:
- Averaging all the embeddings: This is faster but might introduce some noise by blending different pieces of information.
- Searching and re-ranking: Each hypothetical document is searched individually, and the results are then re-ranked to find the most relevant.
Note that the hypothetical documents generated are not stored; they are solely used to enhance the embeddings of the user query. Once the search process is complete, these documents are discarded, as they may contain inaccurate or fabricated information. Their purpose is purely to improve the retrieval quality without persisting them in the system.
RAG Fusion
In RAG Fusion, query rewriting creates different versions of a user’s query, allowing the system to approach the search from multiple angles. These rewrites can target different types of search strategies—some focusing on short, keyword-based queries, while others use longer, sentence-based queries. Additionally, different rewrites may capture various parts of a complex question.
For example, in a query about “renewable energy policies”, one rewrite might emphasize the economic impact, while another focuses on the environmental aspect. By generating these variations, the system ensures broader document coverage.
The results are then combined using Reciprocal Rank Fusion (RRF), which gives higher importance to results that are ranked well across multiple query rewrites. This process maximizes both relevance and diversity in the final answer, providing a comprehensive response to the user query.
Here is a diagramm that shows how RAG Fusion works:
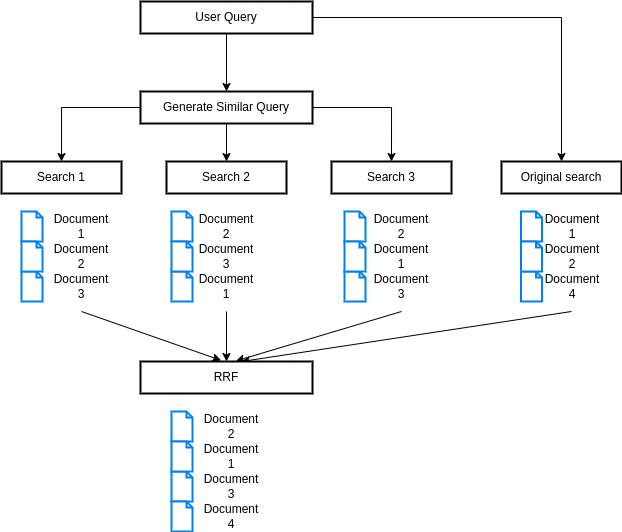
The implementation of this technique closely resembles the approach used in HyDE. However, it’s important to note that you will need to have a vector store in place, complete with a search function, to proceed to an embedding-based search.
First we need to create a prompt system:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
PROMPT_SYSTEM = f"""You are a highly advanced AI specializing in query reformulation for information retrieval for EU Law. Your task is to generate {k} alternative queries based on a user's original query.""" + """ These alternative queries should be closely related to the original query but should vary in wording or focus to capture a broader range of relevant documents. Each alternative query should be clear and distinct.
Format the output as a JSON array where each element is a new query. For example:
{
"original_query": "What are the key provisions of the GDPR?",
"alternative_queries": [
"Main articles of the GDPR",
"What are the major GDPR rules?",
"Important GDPR articles",
"GDPR compliance requirements"
]
}
Always output your answer in JSON format with no preamble.
"""
Once we have all the alternative queries, we can search every query parrallely (replace the search function with your embedding search):
1
2
3
4
5
6
7
8
9
10
import concurrent
documents = {}
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = {executor.submit(search, query, size): query for query in queries}
for future in concurrent.futures.as_completed(futures):
query = futures[future]
result = future.result()
documents[query] = result
Finally, we can rerank the documents (doc_id is the elasticSearch id for the document):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
unique_documents = {}
for query, results in documents.items():
results = results[0]
for rank, doc in enumerate(results):
doc_id = doc['id']
if doc_id not in unique_documents:
unique_documents[doc_id] = {'document': doc, 'ranks': []}
unique_documents[doc_id]['ranks'].append({'query': query, 'rank': rank+1})
def rrf(documents, k=60, size=5):
def calculate_rrf_score(ranks, k):
score = 0
for rank_entry in ranks:
rank = rank_entry['rank']
score += 1 / (k + rank)
return score
scored_docs = []
for doc in documents:
score = calculate_rrf_score(doc['ranks'], k)
scored_docs.append((doc['document'], score))
scored_docs.sort(key=lambda x: x[1], reverse=True)
return [doc for doc, score in scored_docs[:size]]
In this code snippet, we implement RRF to enhance document ranking. The process involves first gathering document IDs and their ranks from multiple queries. Each document is then scored using the RRF formula, which favors documents ranked highly across different queries.
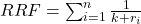
Where:
- ri is the rank of the document for a given query,
- k is a constant that reduces the influence of lower-ranked results,
- The sum is computed across all queries where the document appeared.
This formula ensures that documents ranked highly across multiple queries receive higher scores, leading to better overall ranking results.
Comparison with classic RAG
After presenting and implementing the methods, we now move to a comparison of the different RAG systems: RAG Fusion, HyDE, and Classic RAG. In the Classic RAG setup, results are based purely on the top 5 document chunks ranked by their embedding similarity to the query. The Elasticsearch index contains 15,000 documents used for retrieval.
To evaluate these techniques, we created a benchmark using 20 questions about European laws. Each RAG system, powered by Claude 3-haiku, generates five answers per question, and a GPT-4o model ranks which answer contains the most detail. The RAG system earns 1 point if it wins in at least two out of five generations, allowing for possible ties. This approach ensures a fair and unbiased comparison.
HyDE vs Classic RAG
Below are the results of the benchmark for HyDE:
| Result | HyDE | Classic RAG |
|---|---|---|
| Wins | 10 | 6 |
| Draws | 4 | 4 |
Overall, HyDE outperformed Classic RAG, winning more questions and proving to be more effective at retrieving detailed and relevant information in this test dataset. The number of draws suggests that while Classic RAG is still competitive, HyDE has a clear edge in terms of generating more comprehensive responses.
In this instance, HyDE delivered more comprehensive details compared to classic RAG. Interestingly the LLM had prior knowledge of the Ecodata project, making the hypothetical documents generated by HyDE quite close to the actual documents.
RAG fusion vs RAG
Below are the results of the benchmark for RAG fusion:
| Result | RAG Fusion | Classic RAG |
|---|---|---|
| Wins | 10 | 5 |
| Draws | 5 | 5 |
Overall, RAG Fusion significantly outperforms Classic RAG, winning twice as many questions. The number of draws (5) indicates that in certain cases, both systems can provide comparable results, but RAG Fusion consistently delivers more robust answers.
Example Comparison
To better understand the differences between the systems, let’s take a closer look at a specific example from the dataset where both HyDE and RAG Fusion outperformed Classic RAG. The question asked was: “What was the purpose of the Ecodata project?”.
Here are the responses from each system:
Classic RAG:
1
2
3
4
5
6
7
8
The purpose of the Ecodata project was the creation of a databank on ecological
tourism in Europe. Specifically:
The applicant, IPK-München GmbH, submitted a proposal to the European Commission
for "the creation of a databank on ecological tourism in Europe. That databank
was to be called 'Ecodata'." The project was intended to establish this
centralized database on ecological tourism that would be accessible to users
across Europe.
HyDE:
1
2
3
4
5
6
7
The purpose of the Ecodata project was to create a databank on ecological
tourism in Europe. The project was proposed by the applicant, IPK-München GmbH,
and was to be carried out in collaboration with three partner companies
- Innovence (France), Tourconsult (Italy), and 01-pliroforiki (Greece).
The project was planned to last 15 months and included an initial planning phase,
an 8-month development and pilot phase, and a final 3-month evaluation and
expansion phase.
RAG Fusion:
1
2
3
4
5
6
7
8
9
10
11
12
The purpose of the Ecodata project was the creation of a databank on ecological
tourism in Europe. Specifically:
The applicant, IPK-München GmbH, submitted a proposal to the European Commission
to create a databank called "Ecodata" that would provide information on
ecological tourism in Europe. The applicant was to be responsible for
coordinating the project, and would collaborate with three partner companies
from France, Italy, and Greece to carry out the work.
The goal of the Ecodata project was to establish this centralized database on
ecological tourism that could be accessed across Europe. It was intended to be
a pilot scheme to test the feasibility of such a system.
The main differences were:
-
Classic RAG produced a fairly detailed response, but it lacked depth. It provided a general overview of the project and its goal (creating a databank) but didn’t go into the specifics of the collaboration or timeline.
-
HyDE enriched the response by adding details, such as the names of the partner companies and the timeline for the project (15 months, with specific phases for development and evaluation).
-
RAG Fusion combined the strengths of Classic RAG and HyDE, offering detailed information on the purpose of the project, the partner companies involved, and the pilot nature of the initiative. It also emphasized the intended use of the database and the project’s role in testing the feasibility of such a system.
In conclusion, RAG Fusion provided the most well-rounded answer, blending depth and context, while HyDE was more detailed than Classic RAG, offering richer insights into the project timeline and structure.
Conclusion
These methods are valuable to consider when building a RAG system, as they can significantly improve results. However, it’s important to note that their effectiveness depends heavily on the quality and structure of your data, as well as the types of questions you aim to support. Tailoring these techniques to your specific use case maximize their impact.